DeepSeek-V4 发布:1M上下文平权时代与开发者生存指南
2026年4月24日,刚刚发布的 DeepSeek-V4 系列技术报告(Preview 版)不仅是参数的堆砌,更是一场关于“推理效率”的革命。结合 58 页的 PDF 深度报告与官方最新的 X(推特)情报,我为你梳理了这篇万字干货的精华,带你洞察 1M 上下文时代的生存法则。
DeepSeek 发布的这篇 58 页技术报告 —— 《Towards Highly Efficient Million-Token Context Intelligence》,彻底宣告了“百万长文本平权”时代的到来。DeepSeek-V4 预览版不仅推出了 1.6T 参数量的 Pro 版和极致高效的 Flash 版,更在底层架构上通过混合注意力机制击穿了效率屏障。

相关文档
PDF 原始文档地址: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
一、 开启 1M 上下文的“平权时代”
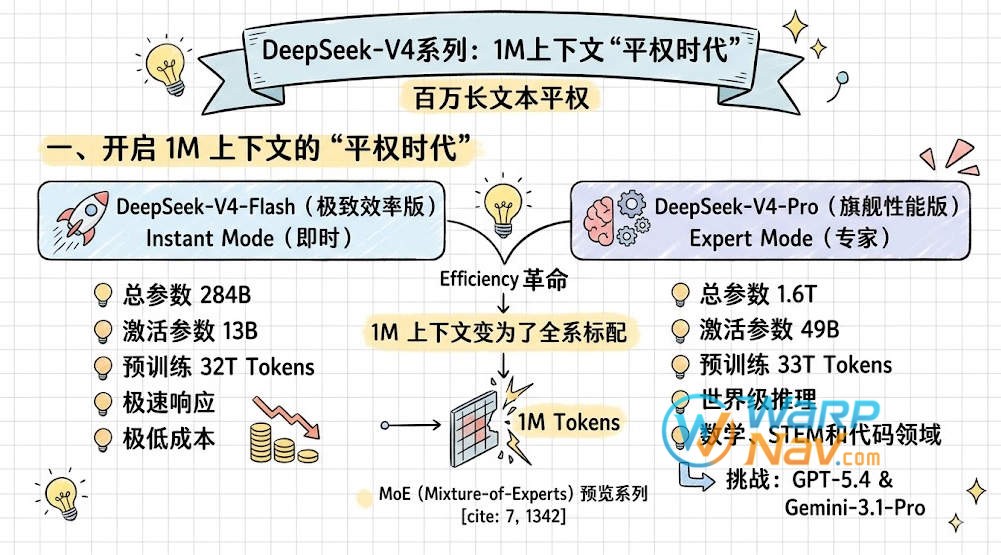
DeepSeek-V4 并非单一模型,而是一个 Mixture-of-Experts (MoE) 预览系列,旨在打破超长上下文处理的效率壁垒。它将 1M(一百万)Token 上下文变为了全系标配,彻底终结了“长文本即昂贵”的历史。
- DeepSeek-V4-Pro (旗舰性能版):总参数 1.6T,激活参数 49B,预训练数据量高达 33T Tokens。它具备世界级的推理能力,在数学、STEM 和代码领域挑战闭源巨头 GPT-5.4 和 Gemini-3.1-Pro。在 Web 端对应 Expert(专家) 模式。
- DeepSeek-V4-Flash (极致效率版):总参数 284B,激活参数仅 13B,预训练 32T Tokens。它是追求极速响应和极低成本的首选,在 Web 端对应 Instant(即时) 模式。
二、 架构革命:混合注意力与流形连接的工业奇迹
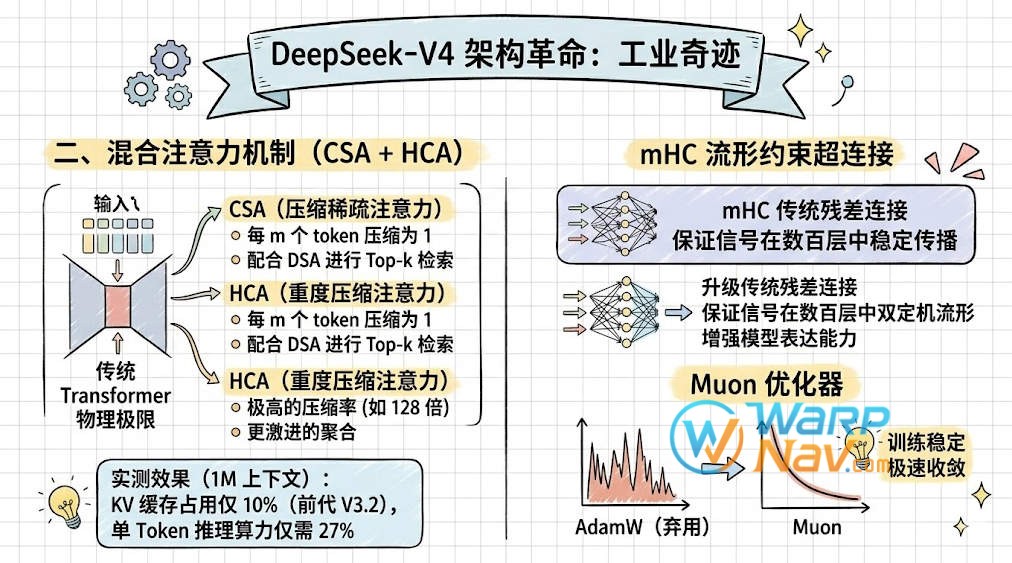
为了处理 1M 长度,传统 Transformer 架构已经遇到了物理极限,V4 在底层动了“大手术” :
- 混合注意力机制 (CSA + HCA):
- CSA (压缩稀疏注意力):将每 $m$ 个 token 的 KV 缓存压缩为 1 条,再配合 DSA(DeepSeek 稀疏注意力)策略进行 Top-k 检索。
- HCA (重度压缩注意力):采用极高的压缩率(如 128 倍),通过更激进的聚合来换取极致的效率。
- 实测效果:在 1M 上下文下,V4-Pro 的 KV 缓存占用仅为前代 V3.2 的 10%,单 Token 推理算力仅需 27%。
- mHC 流形约束超连接:升级了传统的残差连接,将映射约束在“双随机矩阵”流形上。这保证了信号在数百层网络中传播的稳定性,极大增强了模型表达能力 。
- Muon 优化器:在大多数模块中弃用 AdamW,改用 Muon 优化器,在提升训练稳定性的同时显著加快了收敛速度。
三、 通用基础设施:从内核到量化的极限压榨

DeepSeek 为此开发了一套极其强悍的工程栈,专门优化通信与存储瓶颈 [cite: 86]:
- MegaMoE2 通信重叠:设计了融合内核,让 MoE 模块的计算、通信和内存访问完全重叠。在 RL 强化学习等高压场景下,性能提升近 2 倍。
- TileLang 领域特定语言:通过 Host Codegen 技术将 CPU 侧的调度开销从数百微秒降至 1 微秒以内,让底层内核能跑出满载带宽。
- FP4 量化感知训练 (QAT):在 MoE 专家权重和检索路径中全面应用 FP4 量化。这让模型部署时的显存占用大幅缩小,同时保持了 99.7% 的检索召回率。
- DSec 沙盒系统:建立了一个包含 Container 和 microVM 的生产级沙盒平台,支持数十万并发实例,能够精准回放和追踪 Agent 的每一步操作。
四、 训练黑科技:33T Tokens 与预判路由的稳定性保障
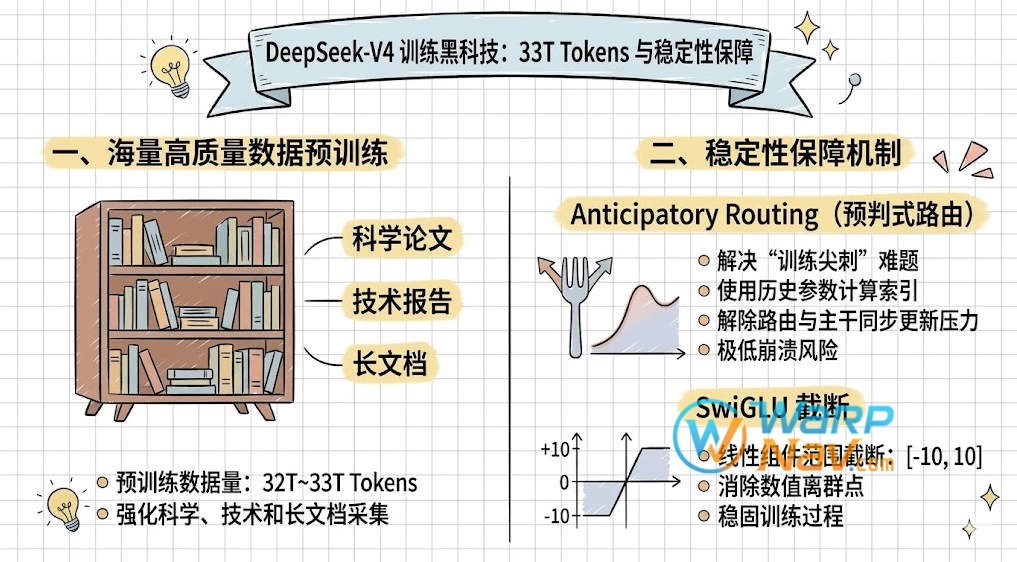
在大规模预训练中,处理万亿级参数 MoE 模型的“训练尖刺”是世界难题:
- 海量数据:基于 32T~33T 高质量 Token 预训练,重点加强了科学论文、技术报告和长文档的采集。
- Anticipatory Routing (预判式路由):在计算路由索引时使用历史网络参数,成功解除了路由网络与主干网络的同步更新压力,将训练崩溃风险降至极低。
- SwiGLU 截断:通过对 SwiGLU 的线性组件进行范围截断([-10, 10]),有效消除了训练过程中的数值离群点,进一步稳固了训练过程。
五、 智能体进化:OPD 蒸馏、三档模式与长程思考
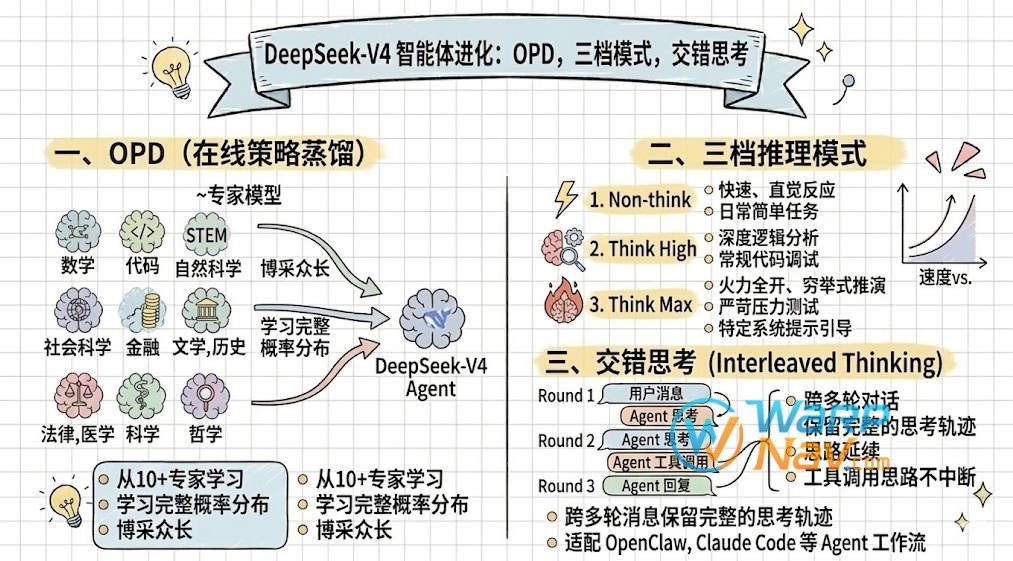
V4 的强大不仅在于预训练,更在于它针对 OpenClaw、Claude Code 等 Agent 工作流的专项适配。
- OPD (在线策略蒸馏):不再使用传统的离线蒸馏,而是让 V4 从 10 多个各领域专家模型中学习完整的概率分布,实现“博采众长”。
- 三档推理模式:
- Non-think:快速、直觉反应,适合日常简单任务。
- Think High:深度逻辑分析,适合常规代码调试。
- Think Max:火力全开,通过特定系统提示引导模型进行穷举式推演和严苛的压力测试。
- 交错思考 (Interleaved Thinking):在 1M 上下文加持下,V4 支持跨多轮用户消息保留完整的思考轨迹。在复杂的工具调用中,模型不会因为新一轮对话就“忘记”之前的解题思路。
六、 生态与未来:API 迁移地图及 2026 路线图
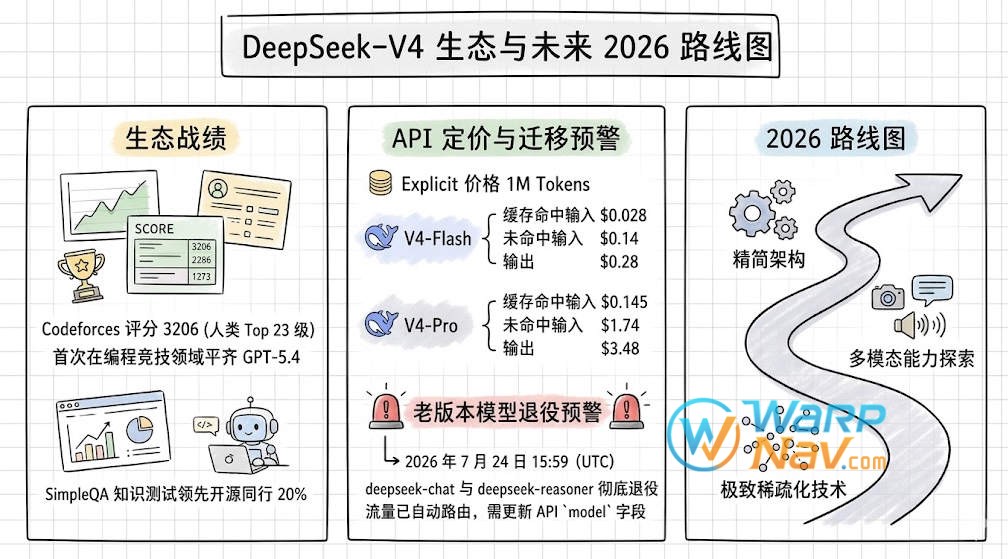
最后,这是关于开发者最关心的 API 动态与模型退役计划。
-
- 战绩斐然:V4-Pro-Max 在 SimpleQA 知识测试中领先开源同行 20%,Codeforces 评分高达 3206(人类 Top 23 级),首次在编程竞技领域平齐 GPT-5.4。
- 激进的 API 定价 (每 1M Tokens):
- V4-Flash:缓存命中输入仅需 $0.028,未命中输入 $0.14,输出 $0.28。
- V4-Pro:缓存命中输入 $0.145,未命中输入 $1.74,输出 $3.48。
- 🚨 重要预警:老版本模型
deepseek-chat和deepseek-reasoner将于 2026 年 7 月 24 日 15:59 (UTC) 彻底退役。目前流量已自动路由至 V4 系列,建议尽快更新代码中的model字段。 - 未来展望:官方下一步将精简架构使其更优雅,并探索多模态能力及更极致的模型稀疏化技术。
智力平权的时代已经开启,权重现已在 Hugging Face 开放。是时候清空你的旧镜像,更新 API 字段,让百万级上下文的生产力真正落地了!
总结:DeepSeek-V4 的技术雄心与开发者的生存法则
DeepSeek-V4 系列技术报告不仅展示了其在模型参数规模上的堆砌(如 Pro 版的 1.6T),更核心的是其在“推理效率”上的革命性突破. 通过发布 Pro 与 Flash 两个版本,DeepSeek 将 1M 上下文变为了标配,正式宣告了“百万长文本平权”时代的到来.
这份报告详细阐述了 DeepSeek 从底层架构到上层应用的全栈优化:
-
架构层面:引入 CSA+HCA 混合注意力机制和 mHC 流形约束超连接,击穿了长文本处理的效率与稳定性屏障 .
-
工程层面:凭借 MegaMoE2、TileLang 和 FP4 量化感知训练(QAT)等强悍工程栈,将内核与量化压榨至极限 .
-
训练层面:利用 33T 高质量 Tokens 以及 Anticipatory Routing(预判式路由)等技术保障了大规模 MoE 训练的稳定性 .
-
智能体进化:通过 OPD 在线策略蒸馏、三档推理模式和交错思考(Interleaved Thinking),显著提升了智能体处理复杂、长程任务的能力 .
在战绩上,V4-Pro-Max 在编程竞技领域(Codeforces 评分 3206)已平齐 GPT-5.4,领先开源同行 . 结合其极其激进的 API 定价(特别是 V4-Flash),DeepSeek 为开发者提供了极具吸引力的长上下文处理方案 .
然而,对于开发者而言,最迫切的“生存法则”在于 API 的迁移:🚨 老版本模型 deepseek-chat 和 deepseek-reasoner 将于 2026 年 7 月 24 日徹底退役,目前流量虽已自动路由至 V4,但开发者必须尽快更新代码中的 model 字段以确保服务的长期稳定性 . 深挖 V4 技术报告背后的效率逻辑,顺应 1M 上下文的大潮,将是开发者在未来生态中占据先机的关键 .
© 版权声明
本站部分内容源于网络收集,文章等版权归原作者所有,若需删稿请联系管理员邮箱:[email protected]
相关文章
没有相关内容!

暂无评论...