
谷歌 Gemma 4 开源大模型正式发布:前沿多模态智能,端侧部署新标杆
2026年4月2日,谷歌 DeepMind 正式推出 Gemma 4 系列开源大模型。这是 Gemma 家族的最新迭代版本,基于 Gemini 技术构建,全面支持文本、图像、音频(部分模型)甚至视频输入,上下文窗口最长达 256K tokens。Gemma 4 被定位为“前沿多模态智能”,强调端侧(on-device)部署、先进推理和代理(agentic)工作流,模型权重完全开源(Apache 2.0 许可),开发者可自由下载、微调和商用。

Gemma 4 模型家族概览
Gemma 4 提供四种参数规模,覆盖从智能手机、浏览器到高性能服务器的全场景需求,分为密集(Dense)和混合专家(MoE)架构:
- E2B(有效参数约 2.3B,总含嵌入 5.1B):超轻量,专为边缘设备、手机、浏览器设计。
- E4B(有效参数约 4.5B,总含嵌入 8B):平衡性能与效率,支持音频处理。
- 31B Dense:高性能密集模型,适合服务器级推理。
- 26B A4B MoE(总参数 25.2B,激活参数仅 3.8B~4B):MoE 架构,高效高吞吐,内存占用低但能力强。
小模型(E2B/E4B)采用 Per-Layer Embeddings(PLE)技术提升参数效率;大模型支持混合注意力机制(滑动窗口 + 全局注意力),并优化 KV Cache 以支持超长上下文。
内存需求(推理估算,仅模型权重,不含 KV Cache):
| 模型 | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) |
|---|---|---|---|
| Gemma 4 E2B | 9.6 GB | 4.6 GB | 3.2 GB |
| Gemma 4 E4B | 15 GB | 7.5 GB | 5 GB |
| Gemma 4 31B | 58.3 GB | 30.4 GB | 17.4 GB |
| Gemma 4 26B A4B | 48 GB | 25 GB | 15.6 GB |
量化后,小模型可在手机或笔记本上流畅运行,大模型适合工作站或云端。
核心能力与亮点
- 多模态输入:全系支持文本 + 图像(可变分辨率/宽高比,图像 token 可配置 70~1120);E2B/E4B 原生支持音频(ASR、AST,最长 30 秒);视频以帧序列处理(最长 60 秒,1 fps)。
- 超长上下文:128K(小模型)/ 256K(大模型),长上下文检索能力显著提升。
- 先进推理与 Agent:内置可配置“思考模式”(<|think|> token),支持函数调用、工具使用、自主代理工作流。编码能力大幅提升,适合代码生成、调试和复杂任务。
- 多语言与安全:覆盖 140+ 语言,训练数据经过严格 CSAM 和敏感信息过滤,安全评估大幅优于 Gemma 3。
- 端侧优先:专为本地运行优化,支持 Transformers、llama.cpp、MLX、WebGPU、Rust 等生态,即时可用。
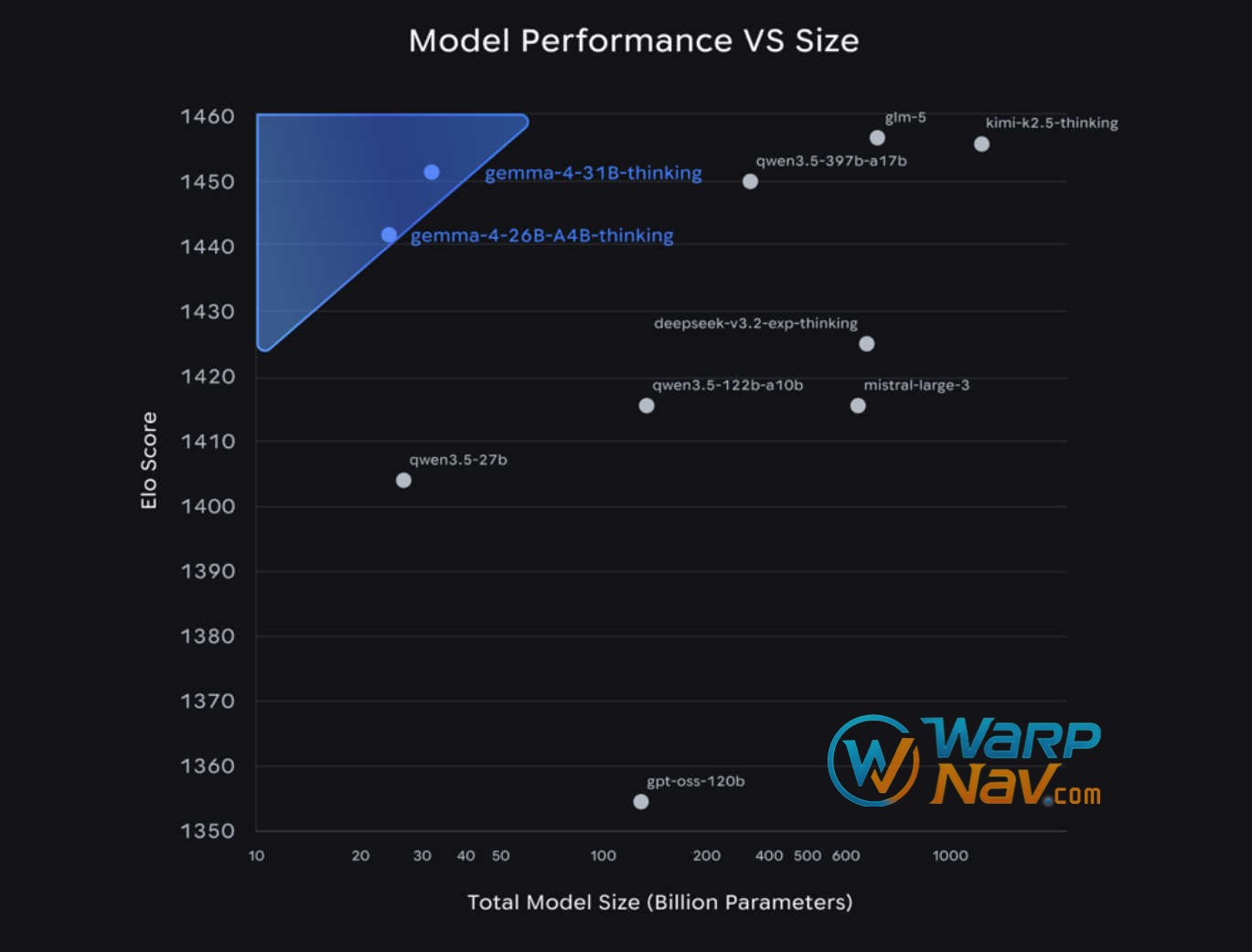
性能基准(指令微调模型)
Gemma 4 在多项前沿基准上达到开源模型 Pareto 前沿,尤其 31B 和 26B 模型表现突出(与 Gemma 3 对比显著提升):
- 通用知识:MMLU Pro 31B 达 85.2%(26B A4B 82.6%)。
- 数学推理:AIME 2026(无工具)31B 89.2%。
- 编程:LiveCodeBench v6 31B 80.0%,Codeforces ELO 2150。
- 视觉:MMMU Pro 31B 76.9%,MATH-Vision 85.6%。
- 长上下文:MRCR v2(128K 8-needle)31B 66.4%。
整体而言,Gemma 4 在同规模下超越前代,并在推理、视觉、音频等领域实现跨越式进步。
许可、下载与生态支持
- 许可:Apache 2.0,完全开放权重,无地域限制,中国开发者可直接访问。
- 下载地址:
- Hugging Face:https://huggingface.co/collections/google/gemma-4(含 base 和 instruction-tuned 版本)
- Kaggle:搜索 “gemma-4” 并由 Google 发布
- 生态:Hugging Face Transformers、llama.cpp(GGUF)、MLX(Apple Silicon)、Transformers.js(浏览器)、mistral.rs(Rust)等均提供 Day-0 支持,支持函数调用和 Agent 框架。
快速上手示例(Transformers):
Python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_id = "google/gemma-4-E4B-it" # 或其他规模
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
# 多模态示例:图像 + 文本
inputs = processor(text="描述这张图片", images=image, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(outputs[0]))实际应用场景
Gemma 4 适合本地隐私保护场景:手机端实时语音转录、文档 OCR、图像分析、代码助手、个人 Agent 等。Hugging Face 演示显示,它能在本地完成对象检测、HTML 生成、视频理解、音频问答等复杂任务,推理速度快、质量高。
总结与展望
Gemma 4 延续了 Gemma 系列“轻量、高性能、开放”的基因,进一步将多模态能力和端侧部署推向新高度。它不仅为开发者提供了媲美闭源前沿模型的工具,还通过完全开源激发全球社区创新。无论你是构建移动 App、桌面 Agent 还是云端应用,Gemma 4 都是值得立即尝试的选择。
模型现已上线,建议立即前往 Hugging Face 或 Kaggle 下载体验。未来,随着社区微调和硬件优化,Gemma 4 有望成为本地 AI 的新标准。
参考来源:Google AI for Developers 官方文档、DeepMind 发布信息、Hugging Face 博客及基准数据(2026 年 4 月最新)。欢迎开发者在评论区分享你的 Gemma 4 部署体验!
© 版权声明
本站部分内容源于网络收集,文章等版权归原作者所有,若需删稿请联系管理员邮箱:[email protected]
相关文章




暂无评论...