![[译文]40天 OpenClaw 养成攻略,从零开始让小龙虾越用越聪明(实战经验+技术栈解析)](https://wn.zmoyun.com/wp-content/uploads/2026/03/1772783757-cover.jpg)
很多人刚开始用 OpenClaw 的时候,都会遇到一个问题:Token 消耗得特别快。明明只是聊了几轮,账单就蹭蹭往上涨。
为什么会这样?这篇文章从输入优化、调用优化、模型选择三个维度,手把手教你把 Token 消耗降下来。
![[教程] OpenClaw省钱优化指南 - 节省90% Token消耗的逻辑原理及方法技巧](https://wn.zmoyun.com/wp-content/uploads/2026/02/1771219828-Snp_2026-02-16-132941.jpg)
一、Token 消耗的底层逻辑
在聊优化之前,先理解 Token 消耗是怎么计算的。用一个简单的公式来理解:
Token 消耗 = (输入 + 输出) × 调用次数 × 模型价格
- 输入:每次请求发送的上下文(System Prompt、工具定义、历史对话等)
- 输出:AI 的回复
- 调用次数:对话轮数、cron 任务触发次数
- 模型价格:不同模型的计费标准
搞懂这个公式之后,优化思路就很清晰了:减少输入、减少不必要的调用、选择性价比更高的模型。
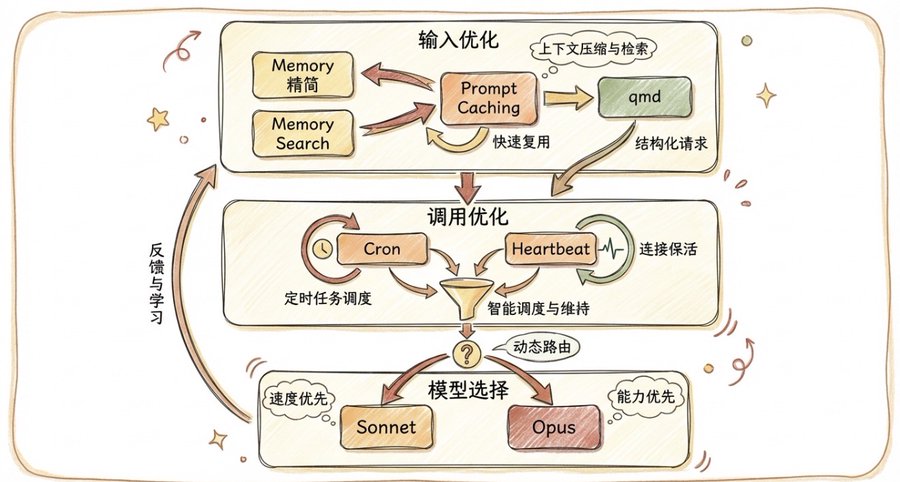
二、输入优化:真正的大头
很多人以为 Token 主要花在 AI 的回复上,但实际上输入才是真正的消耗大头。
OpenClaw 的设计哲学是无状态到有状态的转变,为了让 Agent 像人类一样记住一切,框架每次都会默认将完整对话历史发送出去。一次请求的输入可能就有 2-3 万 tokens,如果聊了 10 轮,那就是 20-30 万 tokens。
下面 8 个方法帮你大幅降低输入成本:
1. 精简 Workspace 文件
OpenClaw 的 Workspace 文件每次对话都会注入,是隐形的 Token 大户。包括 MEMORY.md、AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md 等。
这些文件里可能包含大量用不到的功能说明、白白消耗 tokens。
精简建议:
- AGENTS.md:删掉不需要的部分(群聊规则、TTS、不用的功能),压缩到 800 tokens 以内
- SOUL.md:精简为简洁要点,300-500 tokens
- MEMORY.md:清理过期信息,控制在 2000 tokens 以内
- 定期清理 memory/YYYY-MM-DD.md 中的过期日志
经验法则:每减少 1000 tokens 注入,按每天 100 次调用算,月省约 $45。
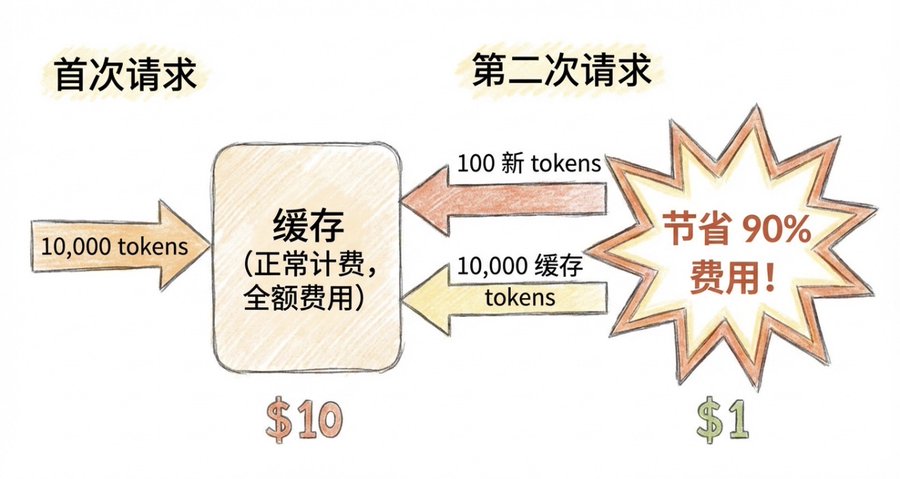
2. 启用 Prompt Caching
Prompt Caching 可以缓存重复的输入内容,能节约 90% 的输入成本。
工作原理:
- 第一次请求:10,000 tokens 输入,正常计费
- 第二次请求:100 tokens 新内容 + 10,000 tokens 缓存
- 100 tokens 正常计费,10,000 tokens 按缓存读取计费(便宜 10 倍)
配置方法:
{
"models": {
"anthropic/claude-opus-4-6": {
"params": {
"cacheRetention": "long",
"maxTokens": 65536
}
}
}
}3. 配置 Heartbeat 保持缓存温暖
Prompt Caching 的缓存时间是 1 小时。如果超过 1 小时没有对话,缓存就会过期,下次对话需要重新缓存。
Heartbeat 机制可以定期发送心跳,保持缓存不过期:
{
"heartbeat": {
"every": "55m",
"target": "last",
"model": "minimax/MiniMax-M2.5"
}
}为什么是 55 分钟?因为缓存时间是 1 小时,55 分钟发一次心跳,可以保持缓存温暖。虽然 Heartbeat 会增加调用次数,但避免了重新缓存的成本,整体是划算的。
4. 使用 Context Pruning 自动修剪
跟 OpenClaw 聊了一整天,到晚上的时候发现它开始变慢,或者突然说上下文太长了?这是因为历史消息一直在累积。
Context Pruning 会自动移除旧的对话内容,保持上下文在合理范围内。配合 Prompt Caching 使用效果更好:
{
"contextTokens": 200000,
"contextPruning": {
"mode": "cache-ttl",
"ttl": "55m"
}
}这个配置的意思是:上下文窗口最大 200K tokens,保留 55 分钟内的对话。超过 55 分钟的旧对话会被自动移除。
5. 使用 Compaction 压缩历史
有时候你需要跟 OpenClaw 进行长时间的深度对话,比如一起完成一个复杂的项目。这种情况下,即使有 Context Pruning,对话历史还是会越来越长。
Compaction 可以把长对话压缩成摘要,让 AI 把重要信息提炼出来,保存到 Memory 文件中,然后再清理历史:
{
"compaction": {
"mode": "safeguard",
"reserveTokensFloor": 24000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 6000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
}
}6. 使用子 Agent 隔离上下文
当你需要让 OpenClaw 并发处理多个独立任务时,比如同时搜索 10 个文件、运行 5 个测试,如果都在主 Agent 里串行执行,不仅慢,而且每个操作都会累积到主 Agent 的上下文中。
子 Agent 的核心优势是:每个子 Agent 有独立的上下文,不会继承主 Agent 的完整对话历史。
{
"subagents": {
"model": "minimax/MiniMax-M2.5",
"maxConcurrent": 12,
"archiveAfterMinutes": 60
}
}7. 启用 Memory Search 精准检索
OpenClaw 用久了,MEMORY.md 和 memory/YYYY-MM-DD.md 文件会越来越大。传统方式是每次对话都读取整个文件,可能有 5000-10000 tokens,但 AI 真正需要的可能只是其中几段。
Memory Search 可以根据当前对话内容,只检索相关的 Memory 片段(约 400 tokens 的块),而不是读取整个文件:
{
"memorySearch": {
"provider": "local",
"cache": {
"enabled": true,
"maxEntries": 50000
}
}
}8. 使用 qmd 进一步减少上下文(进阶)
如果你有大量文档需要检索,可以使用 qmd 作为 memory backend。
qmd 的核心价值:精准检索,只返回相关段落,而不是读取整个文件。
传统方式:一个 500 行文件 3000-5000 tokens,但 Agent 只需要其中 10 行,90% 的 input token 被浪费了。
qmd 方式:建立全文 + 向量索引,精准定位段落,只读取需要的 10-30 行,节约 90% tokens。

三、调用优化:减少不必要的调用
每次对话都是一次 API 调用。虽然我们无法完全避免调用,但可以通过优化来减少不必要的调用。
1. 优化 Cron 任务
Cron 任务每次触发都是一次完整的对话调用,会重新注入全部上下文。一个每 15 分钟跑的 cron,一天 96 次,Opus 下一天可能花费 $10-20。
优化建议:
- 把所有非创作类任务降级为 Sonnet 或免费模型
- 合并同时间段的任务(比如多个检查合为一个)
- 降低不必要的高频率(系统检查从 10 分钟改为 30 分钟)
- 配置 delivery 为按需通知,正常时不发消息
核心原则:不是越频繁越好,大多数”实时”需求是假需求。合并 5 个独立检查为 1 次调用,可以省下 75% 上下文注入成本。
2. 优化 Heartbeat 频率
Heartbeat 虽然能保持缓存温暖,但它本身也是一次 API 调用。如果你设置得太频繁,比如每 10 分钟一次,一天就是 144 次调用。
优化建议:
- 设置工作时间间隔为 45-60 分钟
- 深夜 23:00-08:00 设为静默期
- 精简 HEARTBEAT.md 到最少行数
- 把分散的检查任务合并到 heartbeat 批量执行
四、模型选择:平衡性能和成本
不同模型的价格差距太大,特别是 Claude 模型,价格较高。
策略 1:日常 Sonnet,关键 Opus 手动切换
Sonnet 定价约 Opus 的 1/5,但 80% 日常任务完全够用。
切换命令:
/model sonnet # 切换到 Sonnet /model opus # 切换到 Opus /model haiku # 切换到 Haiku
使用场景:
- Opus:长文写作、复杂代码、多步推理、创意任务
- Sonnet:日常闲聊、简单问答、cron 检查、heartbeat、文件操作、翻译
策略 2:基于频道的差异化配置
在 Discord 或 Telegram 等平台上,可以针对不同的频道设置不同的模型:
- 代码频道:使用高性能模型(Claude Opus)
- 日常聊天频道:使用便宜模型(MiniMax、Gemini Flash)
- 创作频道:使用 Claude Opus,适合长文写作
五、实战:一套完整的优化配置
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-5",
"fallbacks": ["minimax/MiniMax-M2.5", "google/gemini-2.0-flash-exp"]
},
"contextTokens": 200000,
"contextPruning": {
"mode": "cache-ttl",
"ttl": "55m"
},
"compaction": {
"mode": "safeguard",
"reserveTokensFloor": 24000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 6000
}
},
"heartbeat": {
"every": "55m",
"target": "last",
"model": "minimax/MiniMax-M2.5"
},
"maxConcurrent": 6,
"subagents": {
"model": "minimax/MiniMax-M2.5",
"maxConcurrent": 12,
"archiveAfterMinutes": 60
},
"memorySearch": {
"provider": "local",
"cache": {
"enabled": true,
"maxEntries": 50000
}
}
}
}
}这套配置的核心思路:
- 日常任务用 Sonnet(性价比高),用
/model opus手动切换到 Opus - 启用 Prompt Caching(节约 90% 输入成本)
- 配置 Context Pruning 自动修剪上下文
- 配置 Heartbeat 保持缓存温暖
- 启用 Compaction 和 memoryFlush,避免信息丢失
- 启用 Memory Search 精准检索
- 子 Agent 使用免费模型,独立上下文避免爆炸
- 精简 AGENTS.md、SOUL.md、MEMORY.md 文件
总结
回到最开始的公式:
Token 消耗 = (输入 + 输出) × 调用次数 × 模型价格
根据这个公式,优化策略是:
- 输入优化:精简 Memory 文件、启用 Prompt Caching、使用子 Agent 隔离上下文、qmd 语义搜索
- 调用优化:优化 Cron 和 Heartbeat 频率
- 模型选择:日常用 Sonnet,复杂任务用
/model opus切换
最重要的是精简 Memory 文件 + Prompt Caching,这两项就能节约 60-80% 的输入成本。根据使用场景,整体成本可降低 50-90%。
**文章原稿来源:X@ccjing_eth(x.com/ccjing_eth/status/2023030760144503261)
© 版权声明
本站部分内容源于网络收集,文章等版权归原作者所有,若需删稿请联系管理员邮箱:[email protected]
相关文章




暂无评论...