
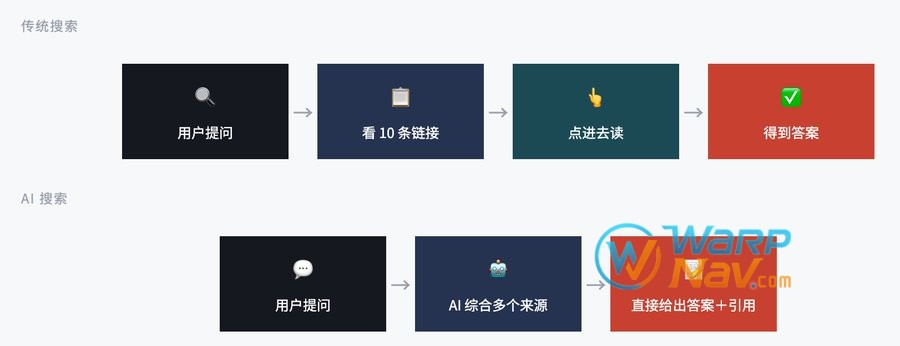
SEO你肯定听过——让谷歌百度把你排到第一页。但 GEO 是什么?简单说,就是让 ChatGPT、豆包、DeepSeek 这类 AI 工具在回答用户问题时,主动引用你的内容。
打个比方:SEO 是”排队拿号,用户看到你再决定要不要点”;GEO 是”AI 替用户做了初步筛选,直接把你的内容包装进回答里”。一个用户在 AI 那里问”预算有限适合做瑜伽的入门装备”,被推过来的需求比传统搜索精准得多——AI 搜索访客转化率是传统搜索的 23 倍。
目前只有约 26% 的营销人在为 AI 引用专门优化内容。这是真实的早鸟窗口——类似 2005 年的 SEO,先做的人会建立很难被追赶的优势。
本文由 WarpNav.com 整理排版后发布,原文信息来自:X @akokoi1
GEO 到底是什么
GEO(Generative Engine Optimization,生成式引擎优化)的目标很明确:让你的内容出现在 AI 工具的回答里,并被引用或推荐。
这个概念最早来自 2023 年 11 月普林斯顿大学团队发表的论文,他们用 10,000 条查询验证了哪些写法能让内容在 AI 回答中被更多引用。到 2025 年,GEO 已成为数字营销主流议题,国内豆包、DeepSeek 等平台的崛起让中文 GEO 优化成为新的关注焦点。
SEO vs GEO:核心区别
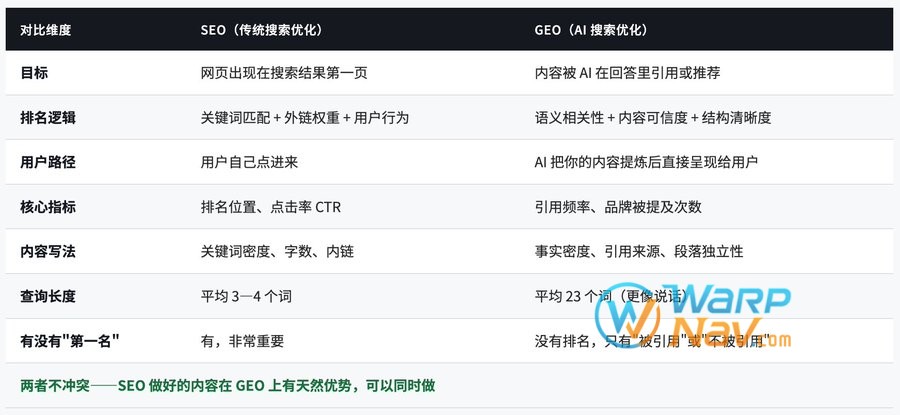
关键认知:GEO 并不是推翻 SEO,是叠加一层新逻辑。Google AI Overviews 的引用仍然高度依赖传统 SEO 信号(96% 的 AI 引用来自权威性强的来源),你现有的 SEO 工作不会白费。
但写法上有本质区别:
❌ 不容易被 AI 引用的写法:
减肥是一个复杂的话题,涉及很多方面,包括饮食、运动、睡眠等各种因素。每个人的情况都不一样,所以没有放之四海而皆准的方法,需要根据个人情况来调整……
✅ 容易被 AI 引用的写法:
成年人每周减重 0.5—1 公斤是健康速率(世界卫生组织 2023 年指南)。核心方法:每日制造 500—750 卡路里热量缺口(减少主食 1/3 + 步行 30 分钟);保证 7—9 小时睡眠(睡眠不足会使饥饿素水平上升 24%,来源:《柳叶刀》2022)……
区别在于:后者每个句子都有具体数字 + 来源 + 独立完整的意思,AI 可以直接截取一句话放进回答里。
AI 怎么选信源
做 GEO 前,得先明白 AI 是怎么工作的——不需要懂技术,知道大概逻辑就够了。
RAG 架构
AI 回答问题的四步流程
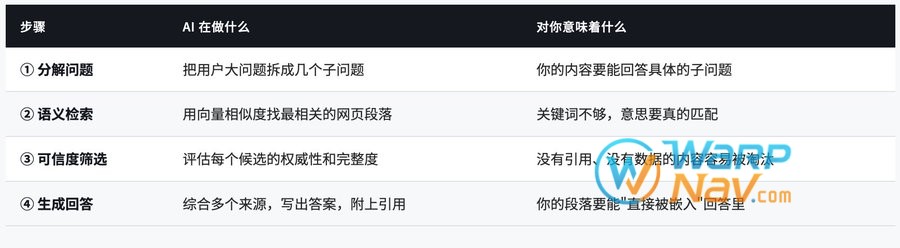
用一个比喻:SEO 是”让图书馆把你的书摆在显眼书架”,GEO 是”让图书管理员在给读者推荐时,能直接念出你书里的某段话”。每一段话都得足够清晰、准确,值得被大声念出来。
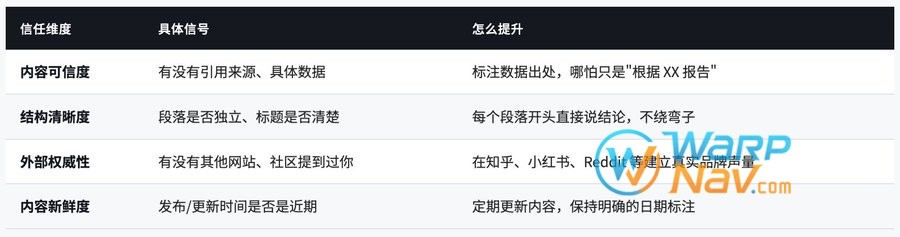
AI 凭什么信任你
Ahrefs 数据显示,80% 的 ChatGPT 引用来源在 Google 搜索前 100 名里找不到。也就是说,即使你的 SEO 做得很差,只要内容写法对,也有机会被 AI 引用。
主流 AI 平台优化策略
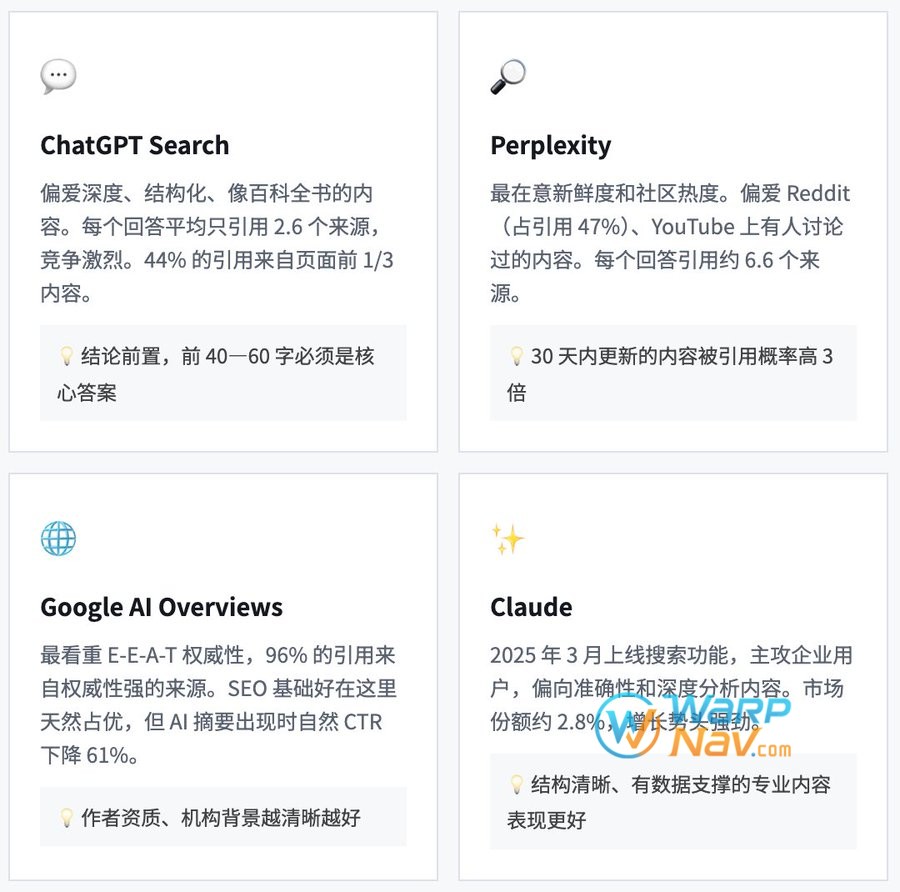
不同平台的”口味”差异很大——同一篇文章在 ChatGPT 和 Perplexity 上的引用逻辑完全不同。只有 11% 的网站能同时被两者引用,说明平台间的来源池几乎互不重叠。
三大通用优化策略
1. 给数据加来源(效果最显著 +115%):
每个数字后面标注”来源:XX 报告 2025 年”。普林斯顿实验证实这是 ROI 最高的单一操作。
2. 结论写在段落开头:
AI 截取的往往是开头 40—60 字,把最重要的话放最前面,不要先铺垫再给答案。
3. 加 FAQ 模块:
在文章末尾列 5—8 个问答。问答格式和 AI 输出格式天然匹配,被引用概率显著更高。
国内 AI 平台专项优化
国内主流 AI 平台(豆包、DeepSeek、Kimi、元宝、千问)的引用逻辑和国际平台完全不同——它们依赖的内容生态、抓取来源、判断权威性的方式都有本质差异。
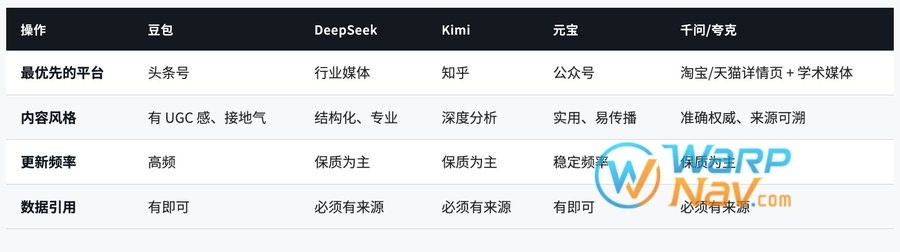
各大平台核心信源与策略
豆包:核心信源为头条号、抖音、抖音百科(字节系)。策略重点:在头条号发布内容,要有层次化设计,融合 UGC 元素(真实用户评价、使用场景)。
DeepSeek:核心信源为行业网站、权威媒体、知名自媒体。策略重点:内容采用结构化数据呈现方式(表格、清单、数据对比),提供深度分析维度。
千问 / 夸克:核心信源为阿里系电商(淘宝/天猫评价)、夸克搜索索引、阿里云盘文档。千问与夸克共用同一套 Qwen 模型,优化一次两端受益。
腾讯元宝:核心信源为微信公众号(36 亿篇文章),与腾讯文档、腾讯会议深度集成。发布高质量公众号文章是最高效路径。
Kimi:核心信源为知乎(UGC 占比最高)+ 搜狐、新浪、网易等主流权威媒体。策略重点:在知乎写有深度的专业回答,同时争取权威媒体报道。
国内平台三大特殊考量
1. 多平台内容一致性更重要:
国内各平台 AI 都会进行”多源交叉验证”——如果品牌在多个独立平台上被一致提及,被 AI 引用的概率是单一来源的 4.7 倍。同一套内容要在头条号、知乎、公众号等多平台分发。
2. 避免过度营销语气:
国内 AI 平台对明显广告味的内容识别度很高,会主动降低引用优先级。内容要写成”有用的信息”,而不是”产品介绍”。
3. 视频内容也会被抓取:
豆包会抓取抖音视频的文字描述、字幕;元宝会抓取视频号内容。给每个视频写完整的文字说明能显著提升 AI 可见性。
技术实操四步
四个让 AI 读懂你网站的配置文件
1. robots.txt
— 先开门迎接 AI 爬虫
robots.txt 是放在网站根目录的纯文本文件,告诉所有爬虫哪些页面可以抓。如果写了 Disallow: /,AI 机器人完全看不到你的内容。
检查方法:访问https://你的域名.com/robots.txt,如果显示 404 说明没有该文件(默认等于全部开放)。
确认没有屏蔽 AI 爬虫:搜索 GPTBot、PerplexityBot、ClaudeBot,看后面是不是 Disallow: /。
# ── 默认规则 ─────────────────────────────
User-agent: *
Disallow: /admin/
Disallow: /login/
Disallow: /api/
Disallow: /private/
Allow: /
# ── OpenAI ─────────────────────────────
User-agent: GPTBot
Allow: /
# ── Anthropic ─────────────────────────
User-agent: ClaudeBot
Allow: /
# ── Perplexity ────────────────────────
User-agent: PerplexityBot
Allow: /
# ── Google AI ─────────────────────────
User-agent: Google-Extended
Allow: /
# ── 国内爬虫 ──────────────────────────
User-agent: QwenBot
Allow: /
User-agent: Bytespider
Allow: /
# ── Sitemap ───────────────────────────
Sitemap: https://yourdomain.com/sitemap.xml2. llms.txt
— 给 AI 的”网站说明书”
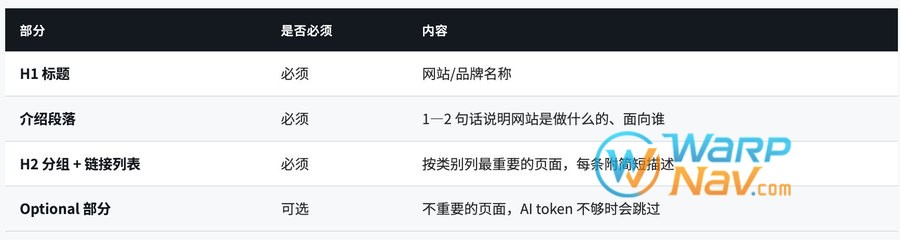
llms.txt 是 2024 年由 fast.ai 的 Jeremy Howard 提出的新标准,格式是 Markdown,放在根目录。它告诉 AI “我的网站有哪些重要内容、怎么理解我”。
# 你的网站名称
> 一两句话介绍网站做什么、面向什么人群。
> 例:我们是专注于个人理财的中文教育平台,面向 25—40 岁的上班族。
## 核心内容
- [文章标题1](https://你的域名.com/文章1/):一句话说明这篇文章讲什么
- [文章标题2](https://你的域名.com/文章2/):一句话说明这篇文章讲什么
## 产品 / 服务
- [产品名称](https://你的域名.com/product/):产品的核心功能和适用场景
## 关于我们
- [关于页](https://你的域名.com/about/):团队背景、专业资质、成立时间
## Optional
> 以下内容不重要,AI 可以跳过
- [标签页](https://你的域名.com/tags/):文章分类标签三条原则:① 每条链接的描述要具体,不要写”点击了解更多” ② 优先列最想被引用的内容 ③ Optional 里的内容 AI 可能跳过,重要内容别放这里
3. Schema 结构化数据
— 用机器能懂的语言描述内容
Schema 是嵌在网页 <head> 里的 JSON 代码,用标准格式告诉搜索引擎和 AI:这篇文章是谁写的、什么时候发布的、是不是问答格式。
Article Schema — 每篇文章都要加:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "你的文章标题(和 H1 保持一致)",
"description": "用 1—2 句话总结文章内容,AI 可能直接引用这段",
"datePublished": "2025-06-01",
"dateModified": "2026-03-27",
"author": {
"@type": "Person",
"name": "作者姓名",
"url": "https://你的域名.com/about/"
},
"publisher": {
"@type": "Organization",
"name": "你的网站或品牌名",
"logo": {
"@type": "ImageObject",
"url": "https://你的域名.com/logo.png"
}
},
"image": "https://你的域名.com/images/文章配图.jpg",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://你的域名.com/这篇文章的URL/"
}
}
</script>FAQPage Schema — 效果最显著,有 FAQ 就要加:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "问题一的完整文字?",
"acceptedAnswer": {
"@type": "Answer",
"text": "回答一,建议 50—200 字,先说结论再展开。"
}
}
]
}
</script>测试方法:用 Google Rich Results Test 免费即时检测 Schema 是否被正确识别。WordPress 用户可用 Yoast SEO 或 RankMath 自动生成,不需要手写代码。
4. FAQ 模块写法
— 最容易被 AI 引用的格式
AI 搜索的本质就是”回答问题”,FAQ 的问答格式和 AI 的输出格式天然匹配——它可以把某个问答直接嵌进自己的回答里,几乎不需要改写。
问题怎么写?(5 条原则)
- 用真实用户的说话方式,不要写”什么是 XX 概念的定义”,要写”XX 是什么意思”
- 第一句话就给答案,不要铺垫
- 回答里要有具体数字,”大概需要一段时间”不如”通常需要 3—7 个工作日”
- 每个问答控制在 50—200 字
- 写 5—8 个问题,质量比数量重要
完整行动清单
按顺序做,最快半天可以完成基础配置:
- robots.txt:访问
你的域名/robots.txt,确认 GPTBot、PerplexityBot、ClaudeBot、Bytespider 没有被 Disallow - llms.txt:根目录新建 llms.txt,Markdown 格式列出 5—10 个最重要页面,每条加一句描述
- Article Schema:给每篇核心文章的
<head>加上 Article JSON-LD,重点填好 dateModified 和 author - FAQPage Schema:有 FAQ 内容的页面额外加 FAQPage JSON-LD
- Schema 验证:用 Google Rich Results Test 确认没有报错
- 内容改写:选 3—5 篇核心文章,改成”结论在前 + 有数据来源”的写法
- 国内平台布局:按目标平台在对应渠道(头条号/知乎/公众号)同步发布核心内容
- 监测设置:在 GA4 里创建渠道分组,追踪来自 chatgpt.com、perplexity.ai、doubao.com 的推荐流量
- 定期维护:每 30 天更新核心内容的数据和日期,保持新鲜度
做完前五步,你已经比 75% 的网站做得更扎实了。llms.txt 目前部署率极低,robots.txt 里主动开放所有 AI 爬虫的网站更少。这些技术配置的竞争密度远低于内容质量,而且是一次性工作。
© 版权声明
本站部分内容源于网络收集,文章等版权归原作者所有,若需删稿请联系管理员邮箱:[email protected]
相关文章

暂无评论...